En mi
post anterior, un usuario me pidió que hiciese un tutorial sobre como instalar Debian Squeeze con una o varias particiones encriptadas. Y bueno, he aquí cumplo con el pedido.
Nota: todos los pasos que sigo aquí son cosas que he aprendido en forma ad-hoc, puede que haya cosas que necesiten correcciones. Por supuesto, se agradece que las dejen en los comentarios =)
Voy a cubrir algunos pasos esenciales y luego saltar directamente hacia la parte del particionado de discos. También vale aclarar que voy a usar el instalador en modo texto sencillamente porque lo encuentro mas cómodo, pero su análogo gráfico es igual de sencillo.
El primer paso es bootear el instalador de Debian Squeeze:
Para hacer las cosas mas interesantes, voy a elegir la opción "expert install".
Y como éste post es en español... usemos español para la instalación.
A partir de ahí, hago un gran salto hasta elegir que componentes del instalador deben descargarse. Y debo ser sincero: éste paso estimo que debe hacerse ya que vamos a particionar manualmente, pero la verdad no sé si es necesario. El componente a cargar es cfdisk-udeb.
Seguimos adelante hasta llegar al particionado de discos.
La primera opción que se nos ofrece es hacer un particionado guiado utilizando todo el disco. Noten que también está la posibilidad de hacer un LVM cifrado en forma guiada.
Pero nosotros vamos a hacer las cosas de forma manual :-)
Para éste ejemplo, utilicé una máquina virtual con VirtualBox. Como la máquina tiene el disco vacío, es necesario hacer algunos pasos previos. Si el disco sobre el que van a instalar Debian Squeeze ya tenía algún sistema operativo, éstos pasos seguramente no les va a tocar hacerlos. La idea aquí es elegir en qué disco (y no en que partición) vamos a instalar nuestro SO.
Como les decía, el disco estaba vacío, por lo que es necesario crear una tabla de particiones. Noten que en la imagen está seleccionado "No", pero obviamente van a necesitar elegir "Sí" :-)
Bien, ya tenemos nuestro disco con tabla de particiones listo para ser usado. Nuestro pŕoximo paso va a ser crear una partición /boot
no encriptada, para poder permitir que el sistema bootee. Seleccionamos el espacio libre de nuestro disco.
Creamos una nueva partición de 100 MB.
La hacemos una partición primaria (aunque es muy posible que funcione sobre una lógica).
Al principio del espacio libre, sólo por gusto.
Por defecto el instalador queire establecer una partición /, por lo que es necesario cambiarle el punto de montaje.
Finalmente, guardamos los cambios.
Hora de configurar los volúmenes cifrados.
Para proceder, es necesario guardar los cambios a los discos.
Y creamos un volumen cifrado.
Elegimos el espacio libre de nuestro disco para crear tal volumen.
Guardamos los cambios.
Y terminamos la creación del volumen cifrado.
Al crear un volumen cifrado, el sistema ofrece sobreescribir los datos actuales con datos aleatoreos. Éste paso no es estrictamente necesario, pero si altamente recomendable.
La sobreescritura de los datos con datos aleatoreos puede tardar
mucho tiempo. Tardé mas de tres horas en éste paso en un disco de 160G. Se puede cancelar en cualquier momento sin problemas aparentes.
Un paso mas que importante: establecer la frase-contraseña para cifrar el disco.
Por supuesto, hay que repetir la misma para validar que se haya escrito correctamente. ¡Y a no olvidársela!
Ahora nos toca configurar el gestor de volúmenes lógicos (LVM).
Otra vez, hay que guardar los cambios.
La idea ahora es crear un grupo de volúmenes y crear dentro de él los volúmenes lógicos que querramos (swap y / en nuestro caso).
Un nombre para el grupo de volúmenes.
Creamos el grupo de volúmenes en nuestra partición encriptada.
Una vez creado el grupo de volúmenes, hay que crear los volúmenes lógicos para la swap y /.
Hay que repetir éstos últimos pasos para crear /. Luego seleccionamos nuestro volúmen lógico para la swap y establecemos una partición de éste tipo en él:
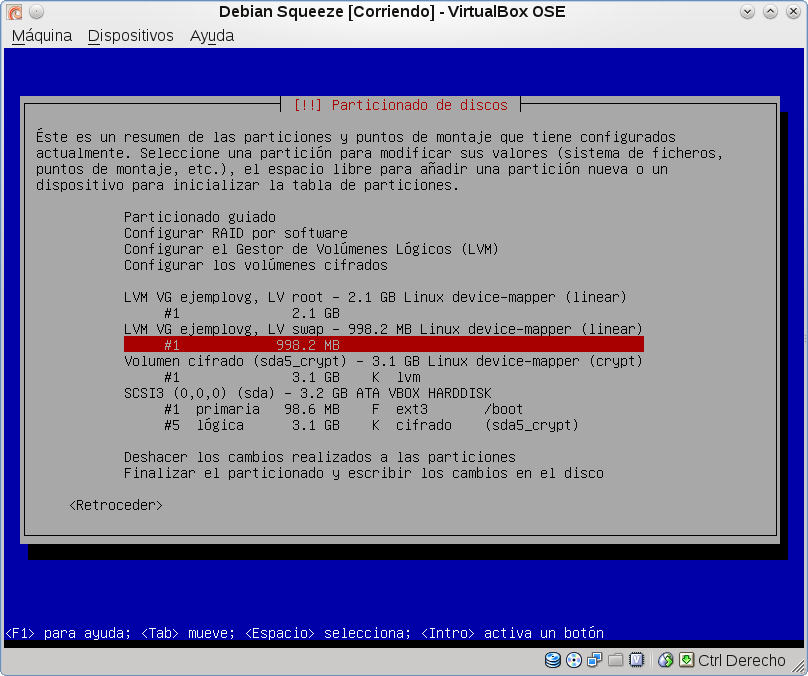
Otra vez, hay que repetir los pasos anteriores para /, normalmente queda como la siguiente figura.
¡Terminamos el particionado! Hora de guardar los cambios.
El resto sigue siendo el mismo proceso de instalación de siempre. Una vez que se reinicia el sistema, podemos ver como se nos pide la frase-contraseña que establecimos antes para poder bootear.
Y eso es todo :-)








































































{kind=link}