Partículas en movimiento
La primera parte del TP era ir a un sitio de Berkeley y bajar el código para simular la interacción entre partículas usando un algoritmo totalmente serial, otro utilizando PThreads y otro OpenMP. Lo primero que hice fué hacer unas corridas y ver los resultados que obtenía.
Nota: cada punto del gráfico es el promedio de 5 corridas del mismo algoritmo con los mismos parámetros. -Esto es válido para todos los gráficos de éste blog post, pero en los datos usados para generar los primeros solo se encuentran los valores ya promediadios.
 |
| Respuesta en tiempo al número de partículas de cada implementación en un servidor Sparc T2 (Niágara2) de 8 cores con 8 hilos livianos cad uno. |
 |
| Respuesta en tiempo al número de partículas de cada implementación en una máquina AMD Athlon 64 X2 Dual Core processor 5000+. |
Notemos que el número de threads de OpenMP no está definido, sino que se toma el de la instalación por defecto (Debian Wheezy en ambas máquinas).
Enseguida podemos notar varias cosas:
- Los algoritmos son O(n²). Nada raro si uno mira el código fuente, los ciclos for anidados saltan a la vista.
- Paralelizar el algoritmo vale la pena a partir de una cierta cantidad de datos. Se podría pensar en ~256 como un buen número de threshold, aunque seguramente es dependiente del hardware y del problema/implementación del algoritmo.
- Crear hilos tiene un costo mínimo asociado. En el caso del Sparc, el costo es mayor, aunque es notable como mejora el rendimiento con OpenMP.
Intentemos mejorar éste desempeño.
Mirando el código fuente vemos que la interacción entre partículas se calcula todas entre todas. Lo interesante es que el resultado de la interacción de una partícula p con una partícula q es la misma pero de signo contrario a la interacción de la partícula q con la partícula p. Entonces podemos hacer los cálculos una sola vez entre dos partículas cualquiera.
Mirando el código fuente vemos que la interacción entre partículas se calcula todas entre todas. Lo interesante es que el resultado de la interacción de una partícula p con una partícula q es la misma pero de signo contrario a la interacción de la partícula q con la partícula p. Entonces podemos hacer los cálculos una sola vez entre dos partículas cualquiera.
Por otro lado, la interacción entre partículas es basada en la distancia entre ellas. Si la distancia es cero, no hay interacción. Entonces una partícula no interactúa con si misma.
Desde el punto de vista del hardware y el paralelismo, podemos utilizar la máxima cantidad e hilos posibles para cada caso. Definitivamente ésto va a traer acarreado mayor tiempo de ejecución en los casos de pocas partículas, pero debería ser mejor a medida que el número de partículas aumenta.
Actualización 18/11/2011: le escribí a Vasily Volkov, responsable del sitio y código de Berkeley arriba linkeado, y tuvo la gentileza de reponderme diciéndome que la licencia en BSD modificada. En el repositorio del código incluyo el mail (en formato mbox) y la licencia propiamente dicha. ¡Gracias Vasily!
Veamos entonces los resultados, empezando por el caso serial.
 |
| Comparación del algoritmo original (1.0.1) con el algoritmo modificado 1.1.6 para el caso serial. |
En éste caso vemos que tanto para Cardumen (Sparc) como para Luna (AMD Athlon) los cambios generaron una reducción del tiempo de ejecución. A su vez, podemos comparar el desempeño de ambos procesadores.
 |
| Comparación del algoritmo original (1.0.1) con el algoritmo modificado 1.1.6 para el caso con OpenMP. |
 |
| Comparación del algoritmo original (1.0.1) con el algoritmo modificado 1.1.6 para el caso con PThreads. |
Aquí también se puede observar el costo que tiene utilizar muchos threads con pocos datos. En éste caso se hace notoria la mejora de rendimiento entre las dos versiones de PThreads en Cardumen.
No puede faltar un gráfico con todos los resultados:
No puede faltar un gráfico con todos los resultados:
 |
| Todos los resultados juntos. |
¿Podemos mejorar aún mas el algoritmo?
Si, y (teóricamente) mucho. El "truco" está en reducir la complejidad del algoritmo lo mas posible. Para eso hay que detectar el cuello de botella, que no es otro que el cálculo de las fuerzas entre cada partícula. Dijimos que la interacción entre las mismas es una relación de la distancia. Pero lo que no nombramos es que, luego de una cierta distancia r, ya no interactúan entre ellas. Debemos entonces encontrar una forma de que cada partícula solo calcule la fuerza que podrían llegar a ofrecerles posibles partículas aledañas.
Una posible solución sería dividir el espacio bidimensional en una matriz donde cada casillero sea de tamaño rxr. Cada vez que se mueve una partícula se la ubica en el casillero correspondiente a su zona final. Luego basta considerar sólo las fuerzas que aplican las partículas en el mismo casillero y en los casilleros aledaños. Si bien suena sencillo, se hace necesario sincronizar el acceso a cada partícula entre los hilos y sus propiedades.
Yo no llegué a implementarlo, pero MorningCoffee si lo ha hecho. Lamentablemente tampoco lo llegué a probar :-(
Haciendo trabajar a Cardumen
Ahora la idea no es analizar el algoritmo sino como responde el servidor con ése algoritmo ante distintas cargas y números de threads.

En el caso de OpenMP podemos ver como se va incrementando el costo fijo de generar una cantidad determinada de threads. Podemos ver que, para muy pocas partículas (hasta ~20), tener un solo hilo de OpenMP (que debería ser el mismo caso que el algoritmo totalmente serial) tiene un overhead.
También se puede observar que dada una cierta cantidad de partículas realmente vale la pena usar paralelización.

El mismo análisis se puede hacer para PThreads.

Y, por supuesto, podemos ver todos los resultados juntos. Las referencias corresponden a la simulación serial, luego las de OpenMP terminando con las de PThreads.
Veamos ahora el speedup de cada caso:

Puede verse que la performance de PThreads es similar.

Resulta posible observar que en ambos casos el speedup se aproxima al teórico para cada número de threads.
¿Y que pasaría si tuviésemos una cantidad fija de threads para utilizar?

¿Tenés los resultados a mano?
Si, pueden obtenerlos acá.
Binarizando imágenes
La idea de la segunda parte del TP es binarizar dos juegos de 100 imágenes de 360 y 1080 pixeles cada uno. Primero resolver el problema de forma serial y luego paralelizarlo. Visto gráficamente, la idea es pasar de una imagen como:
A una imagen con solo dos tonos:
Para lograr ésto usé Qt. no lo hice la manera mas eficiente, ya que utilicé QImage::pixel() y QImage::setPixel(). Podría haber utilizado los métodos de QImage para acceder a los pixeles como vecotres de datos. Pero bueno, para el propósito de éste TP, alcanza. Aproveché el envión que llevo de aprender CMake y lo usé para compilar. Se los recomiendo. El código fuente lo pueden encontrar acá.
La estrategia
Tan sencilla como hacer que cada hilo se ocupe de procesar una imagen. No hay interdependencia entre ellas, por lo que no es necesario sincronizar los threads. Dicho de otra manera, no hay necesidad de procesar las imágenes en ningún orden en particular.
Los gráficos obtenidos
Podemos ver el tiempo de ejecución vs. el número de threads:

Es interesante ver la meseta que se forma entre los ~8 y ~20 threads.

En éste caso, la meseta no aparece.
Y también podemos medir el speedup. En amarillo, el speedup teórico ideal.
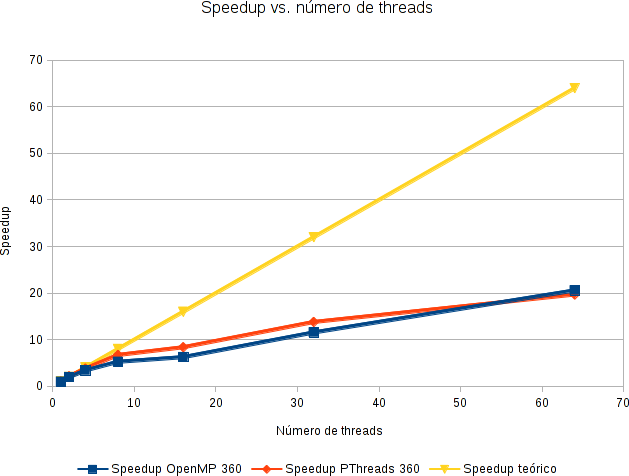

Realmente me sorpendió lo bajo del speedup :-/
Como nota al margen, Cardumen empezó a dar "Bus error" al momento de correr los algoritmos (entre ejecución y ejecución). Es posible que haya un problema de hardware en el mismo.
¿Y los resultados?
También están disponibles acá.
Algunas conclusiones
Si, y (teóricamente) mucho. El "truco" está en reducir la complejidad del algoritmo lo mas posible. Para eso hay que detectar el cuello de botella, que no es otro que el cálculo de las fuerzas entre cada partícula. Dijimos que la interacción entre las mismas es una relación de la distancia. Pero lo que no nombramos es que, luego de una cierta distancia r, ya no interactúan entre ellas. Debemos entonces encontrar una forma de que cada partícula solo calcule la fuerza que podrían llegar a ofrecerles posibles partículas aledañas.
Una posible solución sería dividir el espacio bidimensional en una matriz donde cada casillero sea de tamaño rxr. Cada vez que se mueve una partícula se la ubica en el casillero correspondiente a su zona final. Luego basta considerar sólo las fuerzas que aplican las partículas en el mismo casillero y en los casilleros aledaños. Si bien suena sencillo, se hace necesario sincronizar el acceso a cada partícula entre los hilos y sus propiedades.
Yo no llegué a implementarlo, pero MorningCoffee si lo ha hecho. Lamentablemente tampoco lo llegué a probar :-(
Haciendo trabajar a Cardumen
Ahora la idea no es analizar el algoritmo sino como responde el servidor con ése algoritmo ante distintas cargas y números de threads.
En el caso de OpenMP podemos ver como se va incrementando el costo fijo de generar una cantidad determinada de threads. Podemos ver que, para muy pocas partículas (hasta ~20), tener un solo hilo de OpenMP (que debería ser el mismo caso que el algoritmo totalmente serial) tiene un overhead.
También se puede observar que dada una cierta cantidad de partículas realmente vale la pena usar paralelización.
El mismo análisis se puede hacer para PThreads.
Y, por supuesto, podemos ver todos los resultados juntos. Las referencias corresponden a la simulación serial, luego las de OpenMP terminando con las de PThreads.
Veamos ahora el speedup de cada caso:
Puede verse que la performance de PThreads es similar.
Resulta posible observar que en ambos casos el speedup se aproxima al teórico para cada número de threads.
¿Y que pasaría si tuviésemos una cantidad fija de threads para utilizar?
¿Tenés los resultados a mano?
Si, pueden obtenerlos acá.
Binarizando imágenes
La idea de la segunda parte del TP es binarizar dos juegos de 100 imágenes de 360 y 1080 pixeles cada uno. Primero resolver el problema de forma serial y luego paralelizarlo. Visto gráficamente, la idea es pasar de una imagen como:
 |
| (c) copyright 2008, Blender Foundation / www.bigbuckbunny.org. Bajo licencia CC-BY 3.0. |
A una imagen con solo dos tonos:
 |
| (c) copyright 2008, Blender Foundation / www.bigbuckbunny.org. Bajo licencia CC-BY 3.0. Modificado por mi código :-) |
La estrategia
Tan sencilla como hacer que cada hilo se ocupe de procesar una imagen. No hay interdependencia entre ellas, por lo que no es necesario sincronizar los threads. Dicho de otra manera, no hay necesidad de procesar las imágenes en ningún orden en particular.
Los gráficos obtenidos
Podemos ver el tiempo de ejecución vs. el número de threads:
Es interesante ver la meseta que se forma entre los ~8 y ~20 threads.
En éste caso, la meseta no aparece.
Y también podemos medir el speedup. En amarillo, el speedup teórico ideal.
Realmente me sorpendió lo bajo del speedup :-/
Como nota al margen, Cardumen empezó a dar "Bus error" al momento de correr los algoritmos (entre ejecución y ejecución). Es posible que haya un problema de hardware en el mismo.
¿Y los resultados?
También están disponibles acá.
Algunas conclusiones
- OpenMP hace la vida de un programador mucho mas sencilla que PThreads por poca o nada de diferencia en tiempo de ejecución.
- Esperaba que el Sparc tuviese un mejor rendimiento. Mi sospecha es que no se trata de un servidor diseñado para procesar datos de punto flotante (posee una sola FPU por core, es decir, una FPU por cada 8 hilos).
- Estaría bueno poder decirle a OpenMP/Sistema Operativo que ponga un hilo por core. hasta donde sé, pueden crearse 8 hilos pero no hay ninguna garantía de que cada uno corra en un core. Ésto serviría para reducir el tiempo en cálculos con mucho uso de FPU.
